React18 并发原理
0. 前言
前阵子,打磨已久的React18终于正式发布,其中最重要的一个更新就是并发(concurrency)。其他的新特性如Suspense、useTransition、useDeferredValue 的内部原理都是基于并发的,可想而知在这次更新中并发的重要性。
但是,并发究竟是什么?React团队引入并发又是为了解决哪些问题呢?它到底是如何去解决的呢?前面提到的React18新特性与并发之间又有什么关系呢?
相信大家在看官方文档或者看其他人描述React新特性时,或多或少会对以上几个问题产生疑问。因此,本文将通过分享并发更新的整体实现思路,来帮助大家更好地理解React18这次更新的内容。
1. 什么是并发
首先我们来了解一下并发的概念:
并发,在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行,但任一个时刻点上只有一个程序在处理机上运行。
举个通俗的例子来讲就是:
- 你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。
- 你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。
- 你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。
并行是指两个或多个事件在同一时刻发生;并发是指两个或多个事件在同一时间间隔发生。
并发的关键是具备处理多个任务的能力,但不是在同一时刻处理,而是交替处理多个任务。比如吃饭到一半,开始打电话,打电话到一半发现信号不好挂断了然后继续吃饭,又来电话了...但是每个时刻只会处理一个任务。
在了解了并发的概念后,我们现在思考下,在React中并发指的是什么,它有什么作用呢?
2. React 为什么需要并发
我们都知道,js是单线程语言,同一时间只能执行一件事情。这样就会导致一个问题,如果有一个耗时任务占据了线程,那么后续的执行内容都会被阻塞。比如下面这个例子:
<button id="btn" onclick="handle()">点击按钮</button>
<script>
// 用户点击事件回调
function handle() {
console.log('click 事件触发 ')
}
// 耗时任务,一直占用线程,阻塞了后续的用户行为
function render() {
for (let i = 0; i < 10 ** 5; i++) {
// 创建或更新 DOM 节点
createOrUpdateDom(i)
}
}
window.onload = function () {
render()
}
</script>当我们点击按钮时,由于render函数一直在执行,所以handle回调迟迟没有执行。对于用户来讲,界面是卡死且无法交互的。
如果我们把这个例子中的render函数类比成React的更新过程:即setState触发了一次更新,而这次更新耗时非常久,比如200ms。那么在这200ms的时间里界面处于卡死状态,用户无法进行交互,非常影响用户的使用体验。如下图所示,200ms内浏览器的渲染被阻塞,且用户的click事件回调也被阻塞。
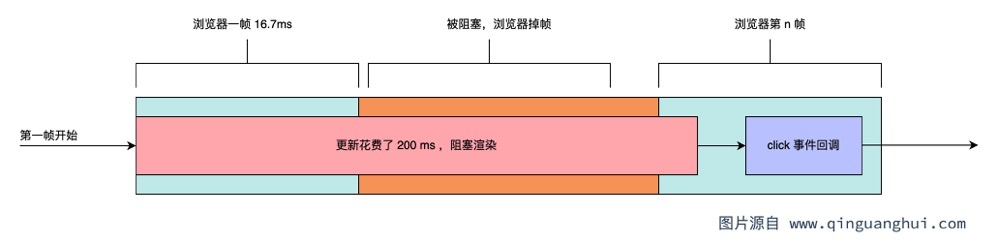
那么该如何解决这个问题呢?React18给出的答案就是:并发。
我们可以将react更新看作一个任务,click事件看作一个任务。在并发的情况下,react更新这个任务到一半的时候,进来了click任务,这个时候先去执行click任务。等click任务执行完成后,接着继续执行剩余的react更新任务。这样就保证了即使在耗时更新的情况下,用户依旧是可以进行交互的(interactive)。
虽然这个想法看上去非常不错,但是实现起来就有点困难了。比如更新到一半时怎么中断?更新中断了又怎么恢复呢?如果click又触发了react更新不就同时存在了两个更新了吗,它们的状态怎么区分?等等各种问题。
虽然很困难,但React18确实做到了这一点:
Concurrency is not a feature, per se. It’s a new behind-the-scenes mechanism that enables React to prepare multiple versions of your UI at the same time.
正如官网中描述的:并发是一种新的幕后机制,它允许在同一时间里,准备多个版本的UI,即多个版本的更新,也就是前面我们提到的并发。下面我们将逐步了解React是怎么实现并发的。
3. 浏览器的一帧里做了什么?
首先,我们需要了解一个前置知识点——window.requestIdleCallback。它的功能如下:
**window.requestIdleCallback()**方法插入一个函数,这个函数将在浏览器空闲时期被调用。
网上有许多文章在聊到React的调度(schedule)和时间切片(time slicing)的时候都提到了这个api。那么这个api究竟有什么作用呢?浏览器的空闲时间又是指的什么呢?
带着这个疑问,我们看看浏览器里的一帧发生了什么。我们知道,通常情况下,浏览器的一帧为16.7ms。由于js是单线程,那么它内部的一些事件,比如 click事件,宏任务,微任务,requestAnimatinFrame,requestIdleCallback等等都会在浏览器帧里按一定的顺序去执行。具体的执行顺序如下:
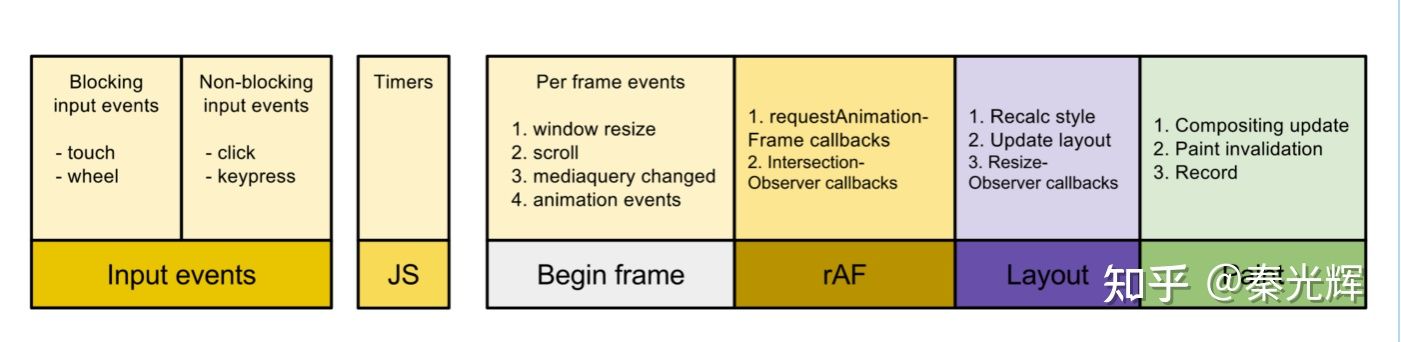
(图片来自这里)
可以发现,浏览器一帧里 js 的执行顺序为:
- 用户事件:最先执行,比如
click等事件的回调。 js代码:宏任务和微任务,这段时间里可以执行多个宏任务,但是必须把微任务队列执行完成。宏任务会被浏览器自动调控,比如浏览器如果觉得宏任务执行时间太久,它会将下一个宏任务分配到下一帧中,避免掉帧。- 在渲染前执行
scroll/resize等事件的回调。 - 在渲染前执行
requestAnimationFrame回调。 - 渲染界面:面试中经常提到的浏览器渲染时
html、css的计算布局绘制等都是在这里完成。 requestIdleCallback执行回调:如果前面的那些任务执行完成了,这一帧还有剩余时间,那么会调用该函数。
从上面可以知道,requestIdleCallback表示的是浏览器里每一帧里在确保其他任务完成时,还剩余时间,那么就会执行requestIdleCallback回调。比如其余任务执行了10ms,这一帧里就还剩6.7ms的时间,那么就会触发requestIdleCallback的回调。
了解了这个方法后,我们可以做一个假设:
如果我们把React的更新(如200ms)拆分成一个个小的更新(如40 个 5ms 的更新),然后每个小更新放到requestIdleCallback中执行。那么就意味着这些小更新会在浏览器每一帧的空闲时间里去执行。如果一帧里有多余时间就执行,没有多余时间就推到下一帧继续执行。这样的话,更新一直在继续,并且同时还能确保每一帧里的事件如click,宏任务,微任务,渲染等能够正常执行,也就可以达到用户可交互的目的。
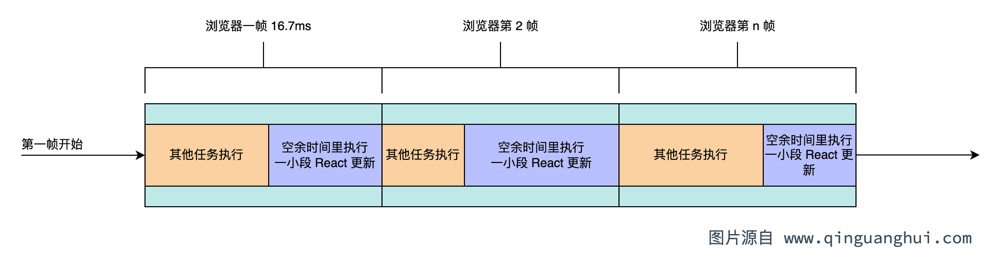
可惜的是,requestIdleCallback 兼容性太差了:

因此,React团队决定自己实现一个类似的功能:时间切片(time slicing)。接下来我们看看时间切片是如何实现的。
4. 时间切片
假如React一个更新需要耗时200ms,我们可以将其拆分为40个5ms的更新(后续会讲到如何拆分),然后每一帧里只花5ms来执行更新。那么,每一帧里不就剩余16.7 - 5 = 11.7ms的时间可以进行用户事件、渲染等其他的js操作吗?如下所示:
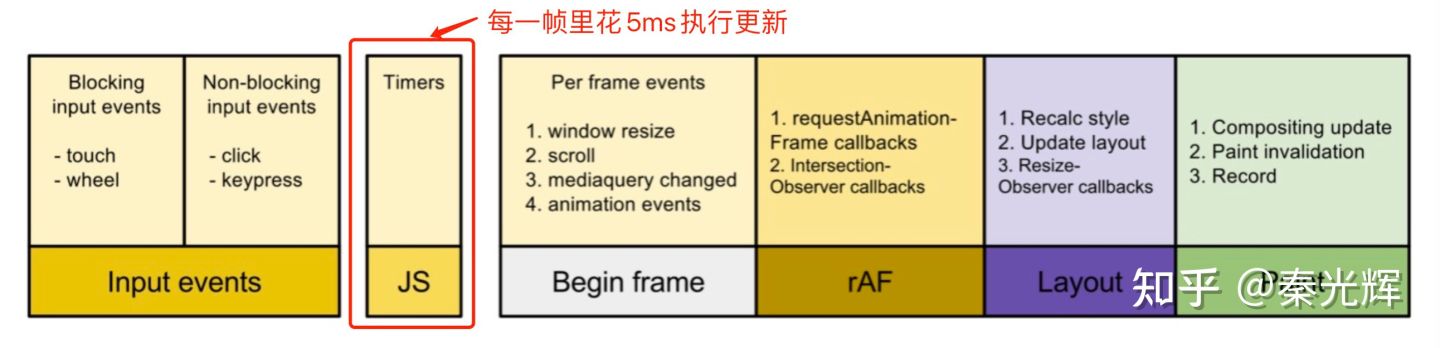
但是,这里就有两个问题:
- 问题1:如何控制每一帧只执行
5ms的更新? - 问题2:如何控制
40个更新分配到每一帧里?
对于问题1,比较容易。我们可以在更新开始时记录startTime,然后每执行一小段时间判断是否超过5ms。如果超过了5ms就不再执行,等下一帧再继续执行。
对于问题2,我们可以通过宏任务实现。比如5ms的更新结束了,我们可以为下一个5ms更新开启一个新的宏任务。浏览器则会将这个宏任务分配到当前帧或者是下一帧执行。
注意,浏览器将宏任务分配到下一帧的这一行为是内置的。比如设置 10000 个 setTimeout(fn, 0),并不会阻塞线程,而是浏览器会将这 10000 个回调合理分配到每一帧当中去执行。
这个分配过程可能像这样:10000 个 setTimeout(fn, 0)在执行时,第一帧里可能执行了300个 setTimeout 回调,第二帧里可能执行了400个 setTimeout 回调,第 n 帧里可能执行了 200 个回调。浏览器为了尽量保证不掉帧,会合理将这些宏任务分配到帧当中去执行。
综上,我们就有下面这种思路了:
- 更新开始,记录开始时间
startTime。 js代码执行时,记录距离开始时间startTime是否超过了5ms。- 如果超过了
5ms,那么这个时候就不应该再以同步的形式来执行代码了,否则依然会阻塞后续的代码执行。 - 所以这个时候我们需要把后续的更新改为一个宏任务,这样浏览器就会分配给他执行的时机。如果有用户事件进来,会先执行用户事件,等用户事件执行完成后,再继续执行宏任务中的更新。
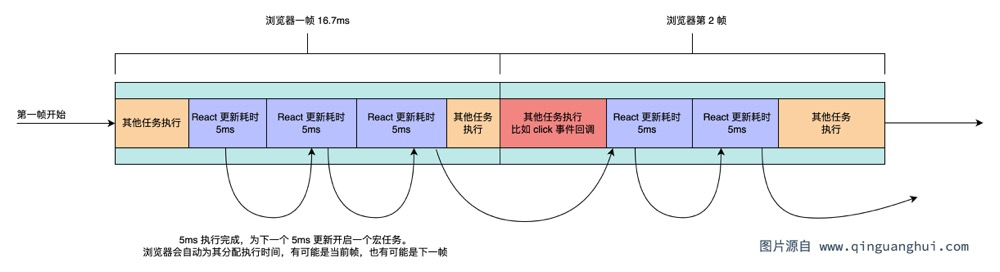
如上图所示,由于更新拆分成了一个个小的宏任务,从而使得click事件的回调有机会执行。
现在,我们已经解决了更新阻塞的问题,接下来就需要解决如何将一个完整的更新拆分为多个更新,并且让它可以暂停等到click事件完成后再回来更新。
5. Fiber 架构
React传统的Reconciler是通过类似于虚拟DOM的方式来进行对比和标记更新。而虚拟DOM的结构不能很好满足将更新拆分的需求,因为它一旦暂停对比过程,下次更新时,很难找到上一个节点和下一个节点的信息。虽然有办法能找到,但相对而言还是比较麻烦。所以,React团队引入了Fiber来解决这一问题。
每一个DOM节点对应一个Fiber对象,DOM树对应的Fiber结构如下:
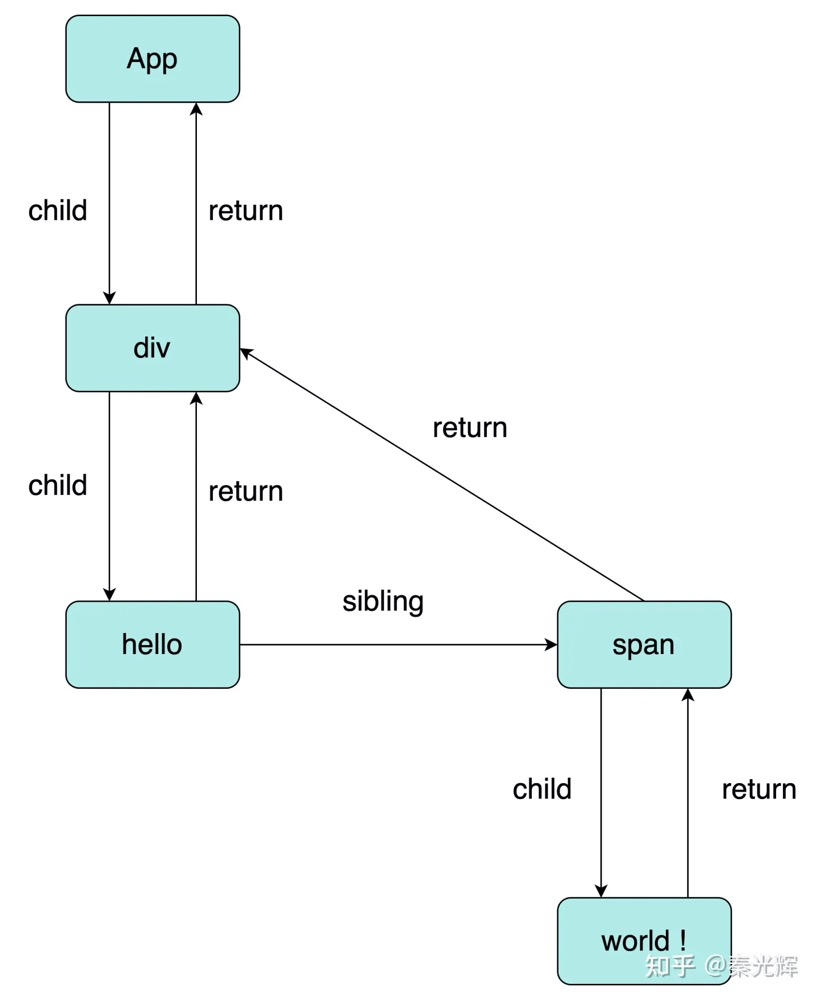
Fiber通过链表的形式来记录节点之间的关系,它与传统的虚拟DOM最大的区别是多了几个属性:
return指向父节点fiber。child指向子节点的第一个fiber。sibling指向下一个兄弟节点的fiber。
通过这种链表的形式,可以很轻松的找到每一个节点的下一个节点或上一个节点。那么这个特性有什么作用呢?
结合上面提到的时间切片的思路,我们需要判断更新是否超过了5ms,以上面这棵Fiber树梳理一下更新的思路。从App Fiber开始:
浏览器第一帧:
- 记录更新开始时间
startTime。 - 首先计算
App节点。计算完成时,发现更新未超过5ms,继续更新下一个节点。 - 计算
div节点。计算完成时,发现更新超过了5ms,那么不会进行更新,而是开启一个宏任务。
- 记录更新开始时间
浏览器第二帧:
- 上一帧最后更新的是div节点,找到下一个节点
hello,计算该节点,发现更新未超过5ms,继续更新下一个节点。 - 计算
span节点,发现更新超过了5ms,那么不会进行更新,而是开启一个宏任务。
- 上一帧最后更新的是div节点,找到下一个节点
浏览器第三帧:
- 上一帧最后更新的是span节点,找到下一个节点
world,计算该节点,更新完成。
- 上一帧最后更新的是span节点,找到下一个节点
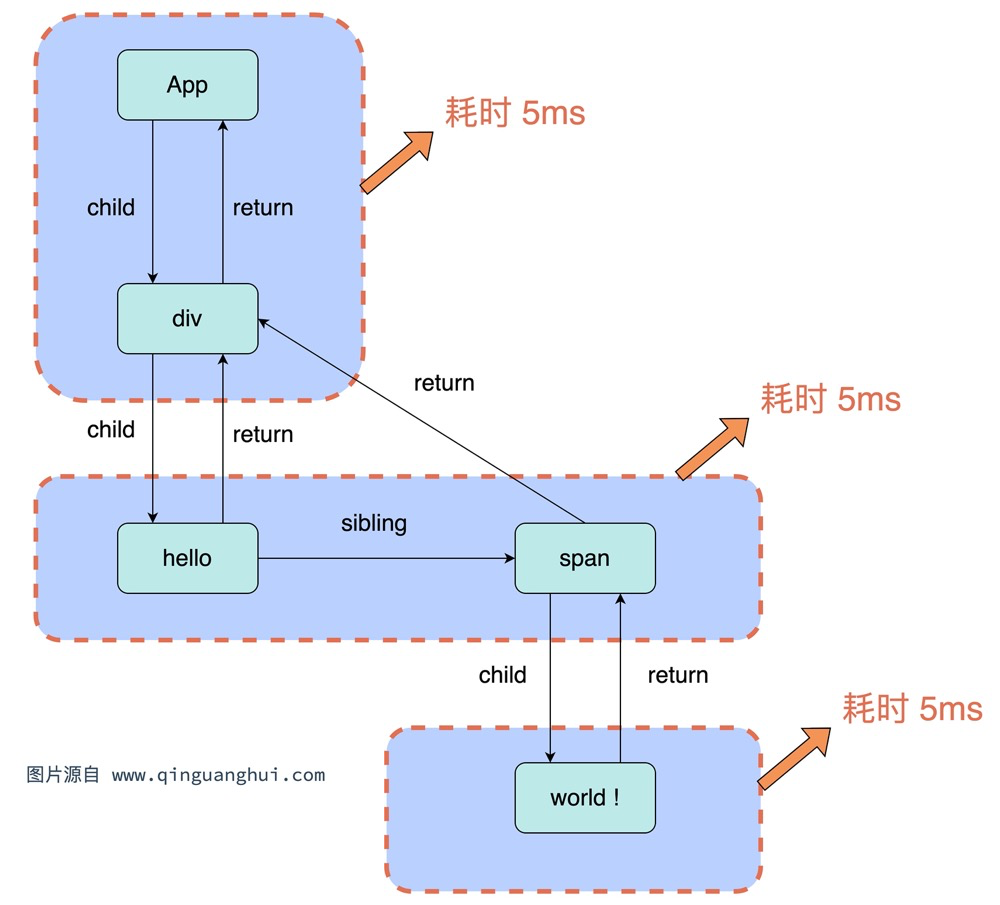
注:
- 实际的更新过程是 beginWork / completeWork 递与归的阶段,与这里有出入,这里仅做演示介绍。
- 这里的更新过程有可能不是第二帧和第三帧,而是在一帧里执行完成,具体需要看浏览器如何去分配宏任务。
- 更新过程分为 reconciler 和 commit 阶段,这里只会将 reconciler 阶段拆分。而 commit 阶段是映射为真实 DOM,无法拆分。
对应浏览器中的执行过程如下:
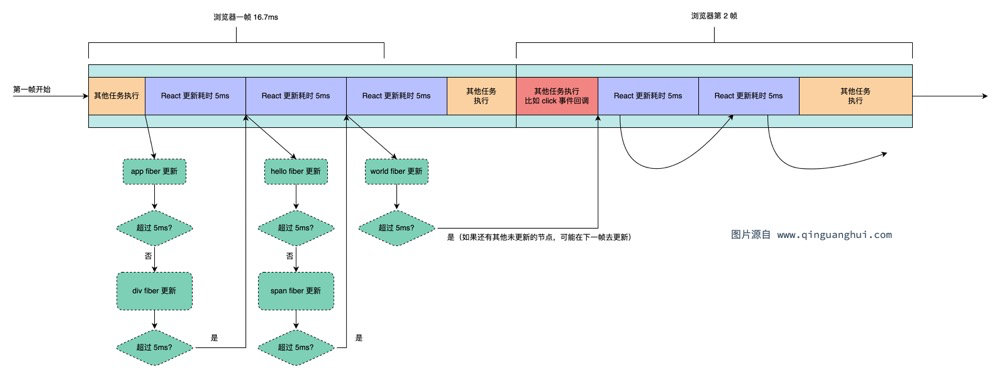
在这个过程中,每个节点计算完成后都会去校验更新时间是否超过了5ms,然后找到下一个节点继续计算,而双向链表恰好切合这种需求。
6. 小结
通过上面的分析,我们可以总结成以下思路:
- 更新时遍历更新每一个节点,每更新一个
Fiber节点后,会判断累计更新时间是否超过5ms。 - 如果超过
5ms,将下一个更新创建为一个宏任务,浏览器自动为其分配执行时机,从而不阻塞用户事件等操作。 - 如果更新的过程中,用户进行触发了点击事件,那么会在
5ms与下一个5ms的间隙中去执行click事件回调。
通过以上步骤,我们能够将现有的同步更新转变为多个小更新分配到浏览器帧里,并且不会阻塞用户事件。接下来看看在React中实际是如何做到的。
7. Scheduler调度
在React中,有一个单独的Scheduler库专门用于处理上面讨论的时间切片。
我们简单看一下Scheduler关键源码实现:
- 首先,在
packages/react-reconciler/src/ReactFiberWorkLoop.new.js文件中:
// 循环更新 fiber 节点
function workLoopConcurrent() {
while (workInProgress !== null && !shouldYield()) {
// 更新单个 fiber 节点
performUnitOfWork(workInProgress);
}
}在更新时,如果是Concurrent模式,低优先级更新会进入到workLoopConcurrent函数。该函数的作用就是遍历Fiber节点,创建Fiber树并标记哪些Fiber被更新了。performUnitOfWork表示的是对每个Fiber节点的处理操作,每次处理前都会执行shouldYield()方法,下面看一下shouldYield方法。
- 在
packages/scheduler/src/forks/Scheduler.js文件中:
export const frameYieldMs = 5;
let frameInterval = frameYieldMs;
function shouldYieldToHost() {
const timeElapsed = getCurrentTime() - startTime;
// 判断时间间隔是否小于 5ms
if (timeElapsed < frameInterval) {
return false;
}
...
}shouldYield()方法会去判断累计更新的时间是否超过5ms,如果超过 5ms,表示需要开启下一个宏任务。
- 最后,在
packages/scheduler/src/forks/Scheduler.js文件中:
let schedulePerformWorkUntilDeadline;
if (typeof localSetImmediate === 'function') {
schedulePerformWorkUntilDeadline = () => {
localSetImmediate(performWorkUntilDeadline);
};
} else if (typeof MessageChannel !== 'undefined') {
const channel = new MessageChannel();
const port = channel.port2;
channel.port1.onmessage = performWorkUntilDeadline;
schedulePerformWorkUntilDeadline = () => {
port.postMessage(null);
};
} else {
schedulePerformWorkUntilDeadline = () => {
localSetTimeout(performWorkUntilDeadline, 0);
};
}如果超过了5ms,就会通过schedulePerformWorkUntilDeadline开启一个宏任务进行下一个更新。这里react做了兼容的处理,实际上是优先使用MessageChannel而不是setTimeout,这是因为在浏览器帧中MessageChannel更优先于setTimeout执行。
总的来说,Scheduler库的处理和前面讨论的时间切片类似。事实上,浏览器也正在做同样的Scheduler库做的事情:通过内置一个api——scheduler.postTask 来解决用户交互在某些情况下无法即时响应的问题,有兴趣的话可以看看相关内容。
最终,通过这种时间切片的方式,在浏览器下的performance面板中,会呈现出如下渲染过程:原本一个耗时的更新(如渲染10000个li标签),被分割为一个个5ms的小更新:
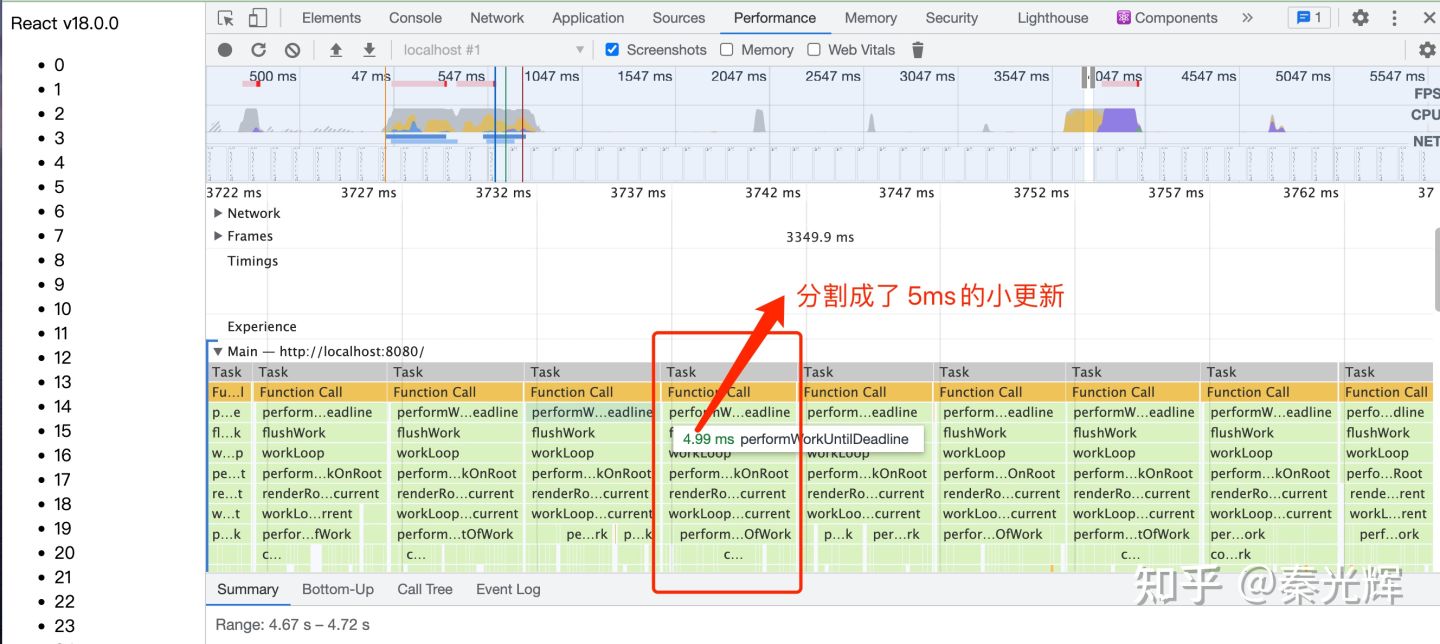
到这里,我们已经清楚了如何让一个耗时的更新不去阻塞用户事件和渲染了。但是这只是有一个更新任务的情况,如果在React更新一半时,click事件进来,然后执行click事件回调,并且触发了新的更新,那么该如何处理共存的两个更新呢?如果click事件的更新过程中,又有其他的click事件触发更新呢?这就涉及到多个更新并存的情况,这也是我们接下来需要讨论的点。
8. 更新优先级
在React中,更新分为两种,紧急更新和过渡更新:
- 紧急更新(
Urgent updates):用户交互等,比如点击、输入、按键等等,由于这些交互的反馈直接影响到用户的使用体验,属于”紧急情况”。 - 过渡更新(
Transition updates):如从一个界面过渡到另一个界面,属于非紧急情况。
对于用户体验来讲,紧急更新应该是优先于非紧急更新的。例如用input搜索时,我们应该确保用户输入的内容是能够是实时响应的,而根据输入值搜索出来的内容在渲染更新的时候不应该阻塞用户的输入操作。
对于没有并发的 React 来讲,搜索后,列表的更新渲染是会阻塞用户输入的,详细例子在最开始有提到。
这里就回到了上面提到的多更新并存的问题:哪些更新优先级高,哪些更新优先级低,哪些更新需要立即去执行,哪些更新可以缓一缓再执行。
为了解决多更新并存问题,React通过lane的方式为每个更新分配了相关优先级。
lane可以简单理解为一些数字,数值越小,表明优先级越高。但是为了计算方便,采用二进制的形式来表示。比如我们在判断一个状态的更新是否属于当前更新时,只需要判断updateLanes & renderLanes即可。
在react-reconciler/src/ReactFiberLane.new.js 文件中,里面一共展示了32条lane:
export const TotalLanes = 31;
export const NoLanes: Lanes = /* */ 0b0000000000000000000000000000000;
export const NoLane: Lane = /* */ 0b0000000000000000000000000000000;
// 同步
export const SyncLane: Lane = /* */ 0b0000000000000000000000000000001;
// 连续事件
export const InputContinuousHydrationLane: Lane = /* */ 0b0000000000000000000000000000010;
export const InputContinuousLane: Lanes = /* */ 0b0000000000000000000000000000100;
// 默认
export const DefaultHydrationLane: Lane = /* */ 0b0000000000000000000000000001000;
export const DefaultLane: Lanes = /* */ 0b0000000000000000000000000010000;
// 过渡
const TransitionHydrationLane: Lane = /* */ 0b0000000000000000000000000100000;
const TransitionLanes: Lanes = /* */ 0b0000000001111111111111111000000;
const TransitionLane1: Lane = /* */ 0b0000000000000000000000001000000;
const TransitionLane2: Lane = /* */ 0b0000000000000000000000010000000;
const TransitionLane3: Lane = /* */ 0b0000000000000000000000100000000;
const TransitionLane4: Lane = /* */ 0b0000000000000000000001000000000;
const TransitionLane5: Lane = /* */ 0b0000000000000000000010000000000;
const TransitionLane6: Lane = /* */ 0b0000000000000000000100000000000;
const TransitionLane7: Lane = /* */ 0b0000000000000000001000000000000;
const TransitionLane8: Lane = /* */ 0b0000000000000000010000000000000;
const TransitionLane9: Lane = /* */ 0b0000000000000000100000000000000;
const TransitionLane10: Lane = /* */ 0b0000000000000001000000000000000;
const TransitionLane11: Lane = /* */ 0b0000000000000010000000000000000;
const TransitionLane12: Lane = /* */ 0b0000000000000100000000000000000;
const TransitionLane13: Lane = /* */ 0b0000000000001000000000000000000;
const TransitionLane14: Lane = /* */ 0b0000000000010000000000000000000;
const TransitionLane15: Lane = /* */ 0b0000000000100000000000000000000;
const TransitionLane16: Lane = /* */ 0b0000000001000000000000000000000;
// 重试
const RetryLanes: Lanes = /* */ 0b0000111110000000000000000000000;
const RetryLane1: Lane = /* */ 0b0000000010000000000000000000000;
const RetryLane2: Lane = /* */ 0b0000000100000000000000000000000;
const RetryLane3: Lane = /* */ 0b0000001000000000000000000000000;
const RetryLane4: Lane = /* */ 0b0000010000000000000000000000000;
const RetryLane5: Lane = /* */ 0b0000100000000000000000000000000;
export const SomeRetryLane: Lane = RetryLane1;
export const SelectiveHydrationLane: Lane = /* */ 0b0001000000000000000000000000000;
const NonIdleLanes = /* */ 0b0001111111111111111111111111111;
export const IdleHydrationLane: Lane = /* */ 0b0010000000000000000000000000000;
export const IdleLane: Lanes = /* */ 0b0100000000000000000000000000000;
// 离屏
export const OffscreenLane: Lane = /* */ 0b1000000000000000000000000000000;不同的lane表示不同的更新优先级。比如用户事件比较紧急,那么可以对应比较高的优先级如SyncLane;UI界面过渡的更新不那么紧急,可以对应比较低的优先级如TransitionLane;网络加载的更新也不那么紧急,可以对应低优先级RetryLane,等等。
通过这种优先级,我们就能判断哪些更新优先执行,哪些更新会被中断滞后执行了。举个例子来讲:假如有两个更新,他们同时对App组件的一个count属性更新:
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
A按钮
</button>
<button onClick={() => startTransition(() => { setCount(count + 1) })}>
B按钮
</button>- 一个是
A按钮:click事件触发的更新,叫做A更新,对应于SyncLane。 - 一个是
B按钮:startTransition触发的更新,叫做B更新,对应于TransitionLane1。
假设B按钮先点击,B更新开始,按照之前提到时间切片的形式进行更新。B更新到一半时,触发了A按钮点击,进而触发A更新。那么此时就会通过lane进行对比,发现SyncLane优先级高于TransitionLane1。此时会中断B更新,开始A更新。直到A更新完成时,再重新开始B更新。

那么React是如何区分B更新对App的count的更改和A更新中对count的更改呢?
实际上,在每次更新时,更新 state的操作会被创建为一个 Update 对象,放到循环链表当中:
export function createUpdate(eventTime: number, lane: Lane): Update<*> {
const update: Update<*> = {
eventTime,
lane,
tag: UpdateState,
payload: null,
callback: null,
next: null,
};
return update;
}在更新的时候就会依次去执行这个链表上的操作,从而计算出最终的state。
从Update的定义可以注意到,每个Update里都有一个lane属性。该属性标识了当前的这个Update的更新优先级,属于哪个更新任务中的操作。
因此当A更新在执行的时候,我们在计算state的时候,只需要去计算与A更新相同lane的Update即可。同样,B更新开始,也只更新具有同等lane级别的Update,从而达到不同更新的状态互不干扰的效果。
9. React18 并发渲染
回顾一下前面讨论的React并发渲染:
为什么需要并发? 因为我们期望一些不重要的更新不会影响一些重要的更新,比如长列表渲染不会阻塞用户
input输入,从而提升用户体验。并发模式是怎样的? 在多个更新并存的情况下,我们需要根据更新优先级,优先执行紧急的更新,其次再执行不那么紧急的更新。比如优先响应
click事件触发的更新,其次再响应长列表渲染的更新。并发模式是如何实现的?
- 对于每个更新,为其分配一个优先级
lane,用于区分其紧急程度。 - 通过
Fiber结构将不紧急的更新拆分成多段更新,并通过宏任务的方式将其合理分配到浏览器的帧当中。这样就能使得紧急任务能够插入进来优先执行。 - 高优先级的更新会打断低优先级的更新,等高优先级更新完成后,再开始低优先级更新。
10. 新特性
接下来看看React18部分并发相关的新api。
Suspense
在v16/v17中,Suspense主要是配合React.lazy进行code spliting。在v18中,Suspense加入了fallback属性,用于将读取数据和指定加载状态分离。那么这种分离有什么好处呢?
举一个例子:
function List({ pageId }) {
const [data, setData] = useState([])
const [isLoading, setIsLoading] = useState(false)
useEffect(() => {
setIsLoading(true)
fetchData(pageId).then((data) => {
setData(data)
setIsLoading(false)
})
}, [])
if (isLoading)
return <Spinner />
return data[pageId].map(item => <li>{item}</li>)
}这是我们最常见的处理异步数据的方式。虽然看上去还能接受,但实际上会有一些问题:
问题一:存储了两套数据isLoading/data和两种渲染结果,并且代码比较冗余,不利于开发维护。如果用Suspense,可以直接读取数据而不关心加载状态,如:
const wrappedData = unstable_createResource(pageId => fetchData(pageId))
function List({ pageId }) {
const data = wrappedData.read(pageId)
return data[pageId].map(item => <li>{item}</li>)
}
// 在需要使用 List 组件的地方包裹一层 Suspense 即可自动控制加载抓昂太
<Suspense fallback={<div>Loading...</div>}>
<List />
</Suspense>可以看出使用Suspense后代码变得简洁清晰易懂,对于开发效率和代码维护性都有很大的提升。
问题二:如果有两个组件Header和List,它们分别有自己的loading状态。现在我们想要把这两个loading状态合并在一起,放到page里。如下所示:
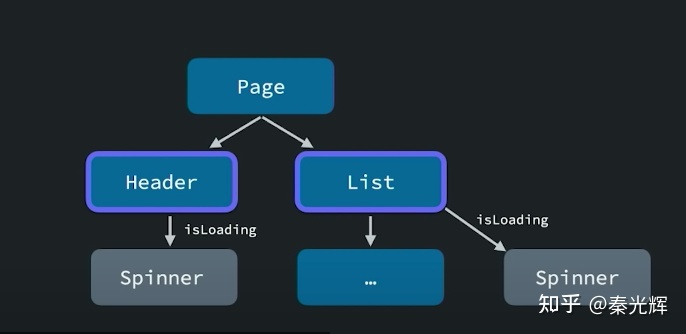
如果按照传统的方式,我们需要将大量的代码移动到上一层page里。但是在React18里,Suspense能够很轻松的解决这一问题:
<Suspense fallback={<Skeleton />}>
<Header />
<List pageId={pageId} />
</Suspense>如果Header组件和List组件都在请求数据当中,那么就会显示Skeleton组件。如果我们想给List组件添加一个单独的占位组件,只需要再套一层Suspense即可实现,无需对数据进行做特殊处理。
<Suspense fallback={<Skeleton />}>
<Header />
<Suspense fallback={<ListPlaceholder />}>
<List pageId={pageId} />
</Suspense>
</Suspense>可以看出,Suspense通过数据和加载状态分离的方式,极大地简化了加载状态的处理。
Suspense 实现
下面我们再看另外一个实际的Suspense使用案例,了解下Suspense如何实现的:
import React, { Suspense } from 'react'
import { unstable_createResource } from 'react-cache'
import { request } from './utils/api'
const data = unstable_createResource(data => request(data))
function AsyncComponent() {
const res = data.read(10000)
return (
<ul>
{Array.from({ length: res }).fill(0).map((_, i) => (
<li key={i}>{i}</li>
))}
</ul>
)
}
function SuspenseComp() {
return (
<Suspense fallback={<div>Loading...</div>}>
<AsyncComponent />
</Suspense>
)
}
export default SuspenseComp在数据读取时我们需要对数据加载的promise通过unstable_createResource方法进行一层封装。其核心目的是为了在promise处于pending状态时会抛出错误,将promise抛出,而Suspense组件会去捕捉这个promise,从而显示fallback,并在promise.then方法中重新触发更新。伪代码如下:
// 抛出错误
function unstable_createResource(promise) {
// 数据没加载完成,抛出 promise
if (promise.status === pending)
throw promise
// 数据加载完成,返回加载完的结果
if (promise.status === fulfilled)
return promise.result
}
// Suspense 捕捉错误,捕捉到抛出的 promise,并添加更新
promise.then(() => {
renderAgain()
})需要注意的是,Suspense捕捉错误后触发的更新为低优先级更新,会通过时间切片的形式去更新,因此不会阻塞用户交互和渲染流程,这也是前面提到的并发更新的一个实际应用。
useTransition/useDeferredValue
useTransition和useDeferredValue其实功能上相差不太多,都是通过时间切片的形式进行更新。关于它们之间的区别,react有做相关描述:
It's tricky. We didn't document useDeferredValue precisely because we don't know how to explain it well yet. So I won't be able to come up with a great explanation on the spot.
startTransition requires you to have access to the place where state is being set. In long term it'll likely mostly be used by code like routers (page navigations) or data fetching libraries (refetching data). Whereas useDeferredValue can be used anywhere because it only takes a value — it doesn't care where the state was set.
useDeferredValue不关心输数据在哪里设置的,它主要用于将一些紧急的事转换为非紧急的事。而useTransition未来可能会用于page navigations或数据获取库等。
那么这两个hook在实际中有什么作用呢?我们看一个实际例子:
import React, { useDeferredValue, useState } from 'react'
function Defer() {
const [searchValue, setSearchValue] = useState(100)
const deferredSearchValue = useDeferredValue(searchValue)
return (
<>
<input
type="number"
value={searchValue}
onChange={(e) => {
setSearchValue(Number(e.target.value) || 0)
}}
/>
{Array.from({ length: deferredSearchValue }).fill(0).map((_, idx) => (
<li key={idx}>{idx}</li>
))}
</>
)
}
export default Defer在input内容改变时,会根据输入内容去渲染一个比较耗时的列表。
- 在传统模式下,由于渲染列表占据了线程,导致用户输入时,无法立即响应。
- 而在
React18中使用useDeferredValue,会将列表渲染的更新置为低优先级更新。并且当input值快速变化的时候,React会合并触发的更新,渲染最后的一个更新。
那么useDeferredValue与防抖节流有什么区别呢?
首先看一下防抖,比如触发onChange事件时,通过setTimeout设置100ms的延迟:
<input onChange={(value) => {
clearTimeout(timer)
timer = setTimeout(() => {
setSearchValue(value)
}, 100)
}}
/>虽然这已经很好的解决了频繁触发渲染的问题,但是还是会存在一些小问题。比如列表渲染非常快时,远远小于100ms,但是却需要等待到100ms后才会开始执行更新。当然,我们也可以尝试节流来解决频繁渲染问题,但是防抖节流都无法解决更新耗时过长的问题。比如列表渲染需要耗时1s,那么在这1s内用户依旧无法去交互。
而useTransition/useDeferredValue很好地解决了这一问题,可以看一下这两个hook源码中比较关键的一部分如下:
const prevTransition = ReactCurrentBatchConfig.transition;
// 每次更新之前,改变优先级,为 transition 优先级
ReactCurrentBatchConfig.transition = {};
try {
setValue(value);
} finally {
ReactCurrentBatchConfig.transition = prevTransition;
}在每次更新之前,会将优先级更新为transition,属于低优先级更新,通过时间切片的形式去更新,从而不阻塞其他紧急的渲染。这在一些耗时渲染和CPU性能相对不高的场景下还是比较有用的,能够稳定保证用户界面是可交互的。
useSyncExternalStore
前面提到的几个新API都是通过并发更新的形式解决渲染阻塞的问题,但是并发同样会带来新的问题。
比如我们将一个低优先级更新拆分成了40个小更新,并且这40个小更新里需要获取全局变量,比如globalVariable = 1。当前20个小更新完成时,这个时候用户点击事件触发,将globalVariable设置为2,那么后续20个小更新在获取这个变量时与前20个更新不一致。这就造成了一个界面对于同一个变量却渲染出了2个值,出现不一致的情况。这种情况我们称之为线程撕裂(tearing)。
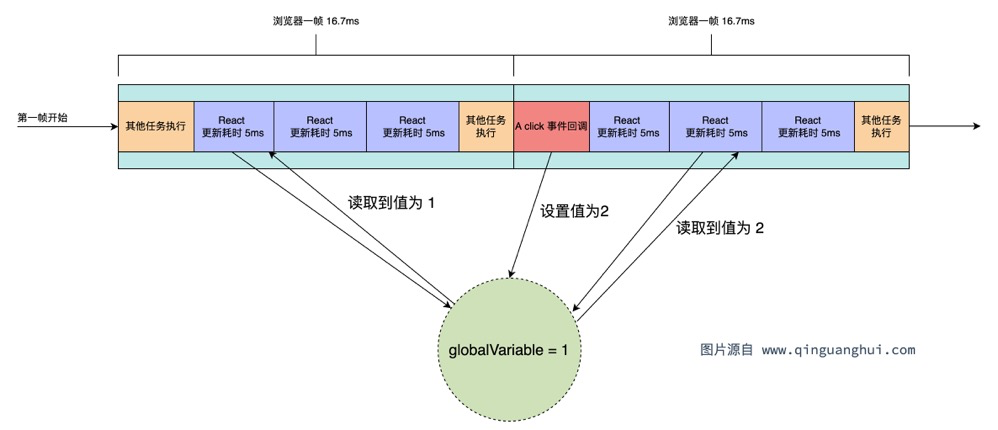
为了解决这一问题,React提供了useSyncExternalStore。它相当于对并发更新使用到的额外数据进行监听,当并发更新时数据发生变化,进行强制渲染:
function updateStoreInstance<T>(
fiber: Fiber,
inst: StoreInstance<T>,
nextSnapshot: T,
getSnapshot: () => T,
) {
// ...
if (checkIfSnapshotChanged(inst)) {
// Force a re-render.
forceStoreRerender(fiber)
}
}当然,这个api是给库作者提供的,用于将库深度整合到React当中,通常不会直接用于实际业务开发当中。
至此,React18的并发原理及相关特性分享完了。总的来说,React18这次的更新大都是底层内容的更新,实际的 api 变动并不是很大。对于开发者来讲,虽然可以很快上手这些新的 api,但是却越来越难以理解背后的一些原理了。
最后,以上部分内容包含我个人的理解,难免存在一些理解上的偏差,如果有错误的地方欢迎大家指正。如果你有什么问题也欢迎讨论。
11. 源码调试
最后附上react v18.0.0的源码调试仓库,该仓库对react 源码做了一点处理,可以直接对源码进行debug调试,相对比较方便。