事件循环、微任务与宏任务
知识要点:
- 单线程的优缺点,以及为什么需要事件循环机制?
- 调用栈和任务队列是怎样的?
- 事件循环机制究竟是怎样的?
- 为什么需要微任务?微任务和宏任务分别是怎样的?
- 微任务和宏任务的执行顺序是怎样的?
单线程的优缺点
javascript是一门单线程非阻塞的语言。单线程的最大好处是不用像多线程编程那样处处在意状态的同步问题。试想一下,如果js是多线程语言,那么同时有两个或多个线程对一个DOM进行处理,DOM该如何展现呢?因此,为了避免这类问题的出现,js选择采用单线程来执行代码,这样就能保证程序的一致性了。
但是使用单线程又会带来新的麻烦:比如由于js和UI共用一个线程,js代码如果长时间执行,势必会导致UI一直无法渲染,这会严重地影响到用户的使用体验。
那么,有没有办法来解决这个问题呢?答案是有的,就是通过异步回调的方式来解决线程阻塞问题。而这就涉及到js中一个非常核心的知识点:事件循环机制(Event Loop)。
调用栈和任务队列
在讲事件循环之前,我们先熟悉一下调用栈和任务队列的概念。调用栈是一种数据结构,用于管理函数的调用关系。如果我们执行一个函数,那么会将这个函数压入到栈中;如果函数执行完毕了,那么会将这个函数从栈中弹出。比如:
function multiply(x, y) {
return x * y;
}
function printSquare(x) {
var s = multiply(x, x);
console.log(s);
}
printSquare(5);刚开始的时候调用栈是空的,紧接着的执行步骤如下:
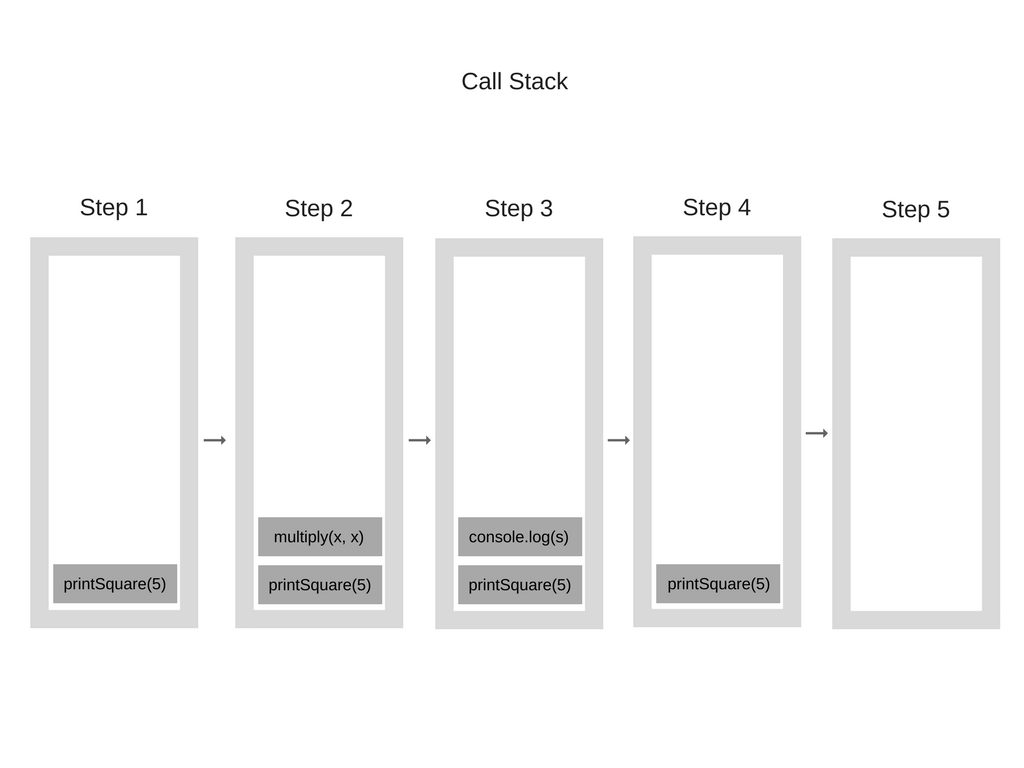
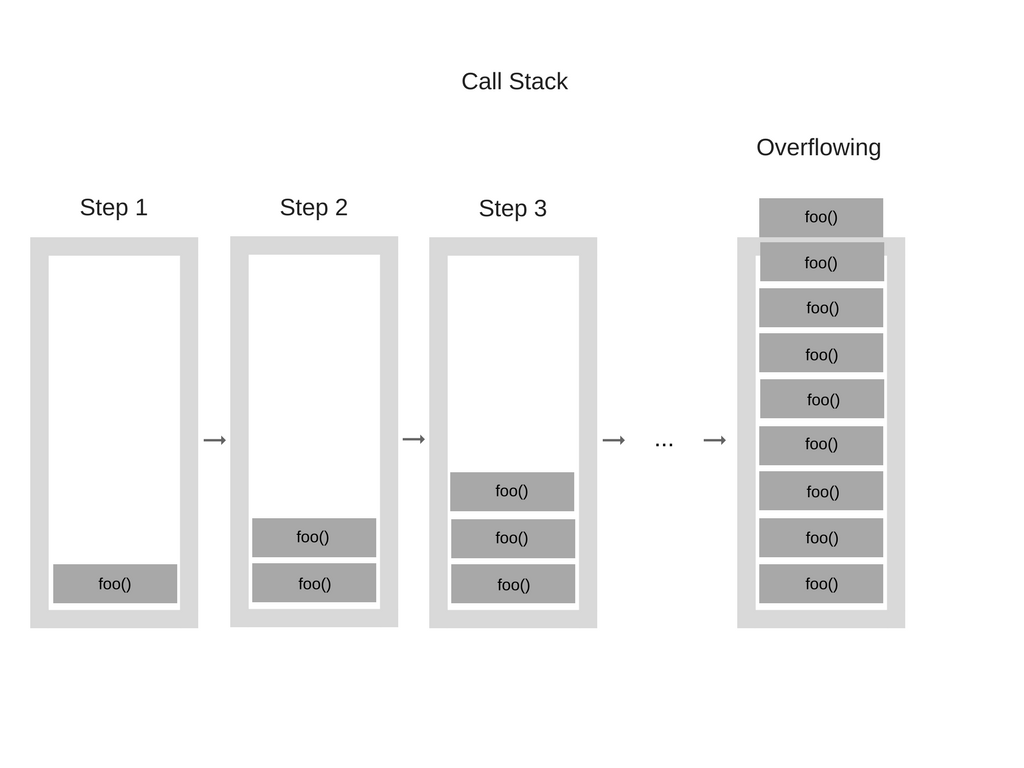
当我们无限循环调用某个函数时,会一直向调用栈内添加调用的函数。当达到一定值的时候,就会超出栈的内存,这就是栈溢出。
以上是同步执行代码的情况,如果遇到异步任务会发生什么呢?我们先看一张图:
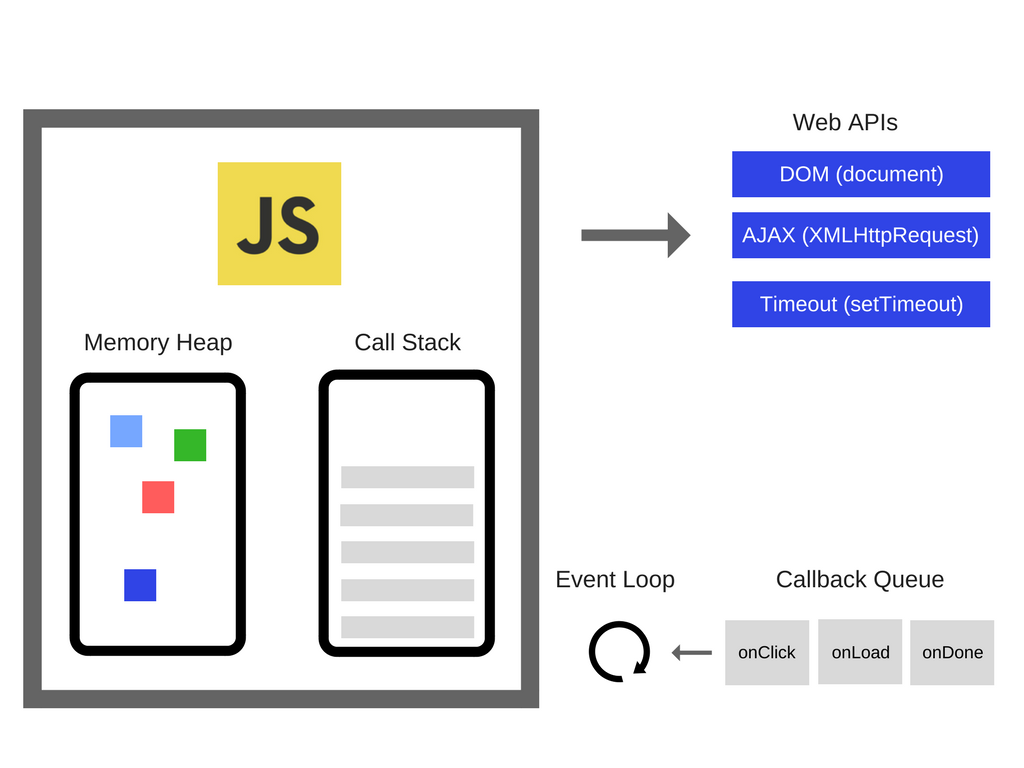
Call Stack指的就是调用栈。
Web APIs代表的js里的异步事件。
Callback Queue则是由回调函数组成的任务队列,用于存放要执行的任务。
任务队列符合队列“先进先出”的特点,也就是说要添加任务的话,添加到队列的尾部;要取出任务的话,从队列头部去取。
但是调用栈、Web APIs和消息队列之间的关系到底是怎样的呢?这就需要我们了解一下事件循环机制了。
事件循环机制
在MDN上,事件循环描述是这样对的:之所以被称为事件循环,是因为它经常按照类似如下的方式实现:
// 等待消息到来
while (queue.waitForMessage()) {
// 处理消息
queue.processNextMessage();
}这里结合上面提到的任务队列,可以理解为事件循环就是不断的从任务队列中取出任务,然后执行任务,等待新任务。让我们来看看下面这段代码具体发生了什么:
console.log(1)
setTimeout(() => { console.log(3) }, 5000)
console.log(2)首先,这整段代码可以看做一个任务,然后会被取出来执行,这里叫做任务A。当遇到setTimeout的时候(也就是调用了Web APIs)的时候,会进行异步执行。而当前任务A会不会等待setTimeout执行,而是继续执行下一段代码,当代码执行完毕时,任务A就算执行完毕了。此时又会从任务队列里取任务,发现没有任务,那么就开始等待。当过了一段时间,setTimeout执行完成后,会将回调函数添加到任务队列里。那么下次从任务队列里取任务时,发现有回调函数,就会取出这个回调函数,记做任务B,然后执行任务B。以此类推...
因此,事件循环就是一个取任务,执行任务,等待任务的循环过程。
宏任务和微任务
为什么要引入宏任务和微任务的概念呢?因为在我们的任务队列中,其实是无法区分优先级的,所有的任务都是按照被添加的时间顺序来排列,这显然不符合一些实时性要求较高的情况。因此,为了解决这个问题,引入了宏任务和微任务的概念,将任务划分了优先级。那么什么是宏任务什么是微任务呢?
这里具体的定义暂时是没有的,但是可以按照异步函数的类型进行大致划分:
宏任务:包含执行整体的js代码,事件回调,XHR回调,定时器(setTimeout/setInterval/setImmediate),IO操作,UI render。
微任务:更新应用程序状态的任务,包括promise回调,MutationObserver,process.nextTick,Object.observe。
接下来着重了解下微任务(microTask)和宏任务(macroTask)的执行顺序,这里有一张图:
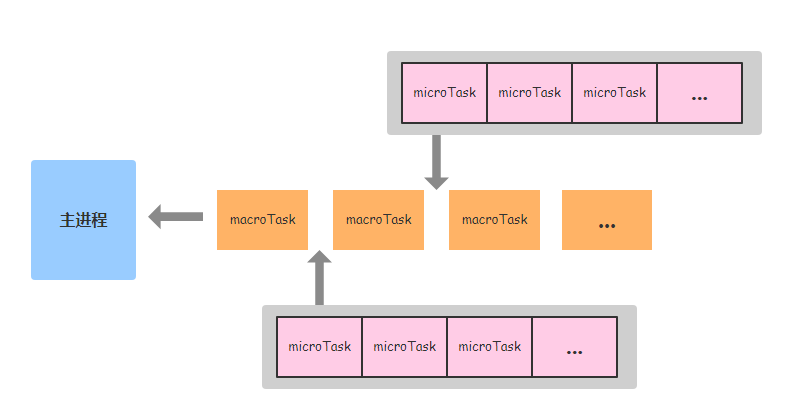
这里的macroTask组成的队列就是上面我们了解的任务队列。从这张图可以看出,每个宏任务之间都会有一个微任务队列。在执行完当前宏任务之后,在取得下一个宏任务之前,就会执行这个微任务队列里的每一个任务。下面我们结合具体例子进行说明:
console.log('start')
setTimeout(function() {
console.log('setTimeout')
}, 0)
Promise.resolve().then(function() {
console.log('promise1')
}).then(function() {
console.log('promise2')
})
console.log('end')首先,我们还是将这整段代码看作一个宏任务,叫做任务
A,执行的时候打印start;当执行到
setTimeout的时候,任务A跳过setTimeout继续执行。而setTimeout会在时间到期后将回调函数添加到任务队列,这里将回调函数记为任务B;当执行到
Promise的时候,任务A跳过Promise继续执行。而将then1添加到任务A之后任务B之前的微任务队列中,记做微任务C。任务
A继续执行,打印end。当代码执行完毕,这个时候会去微任务队列中取任务,因此拿到了任务
C并执行,打印promise1。执行的时候遇到了then2,因此将then2添加到当前微任务队列的末尾,记做任务D。任务C执行完毕。继续从微任务队列中取任务,取到了任务
D并执行,打印**promise2,**任务D执行完毕。继续从微任务队列中取任务,发现没有任务。随后去任务队列中取下一个宏任务,得到任务
B并执行,打印**setTimeout,**任务B执行完毕。重复以上步骤取微任务和宏任务。
因此,最终的打印结果是:
start
end
promise1
promise2
setTimeout通过gif图可以更直观的看下整个执行过程:
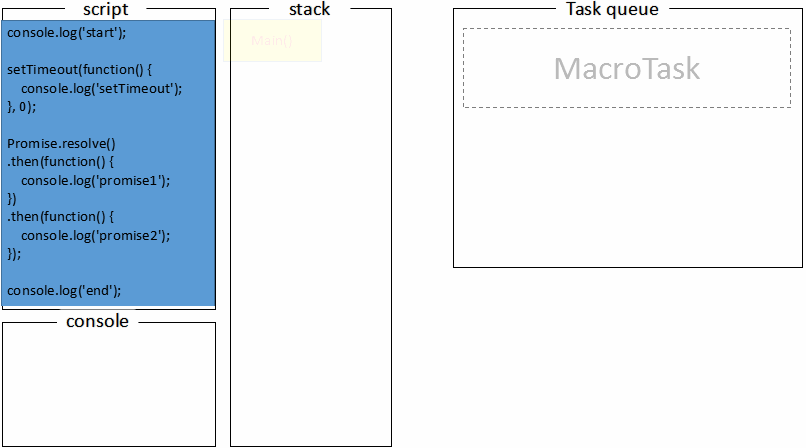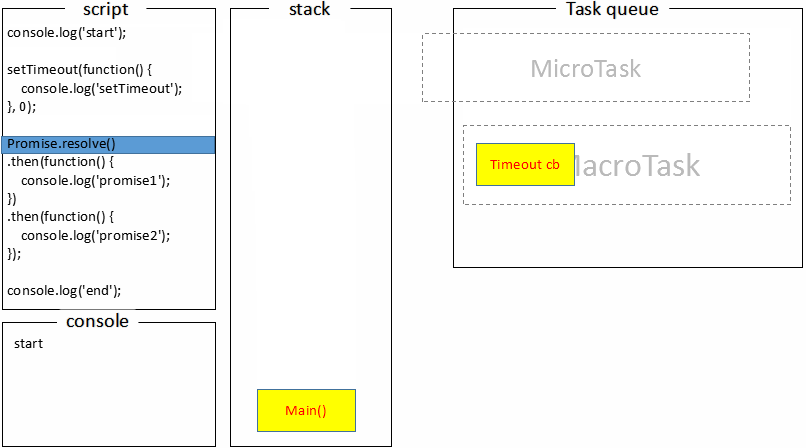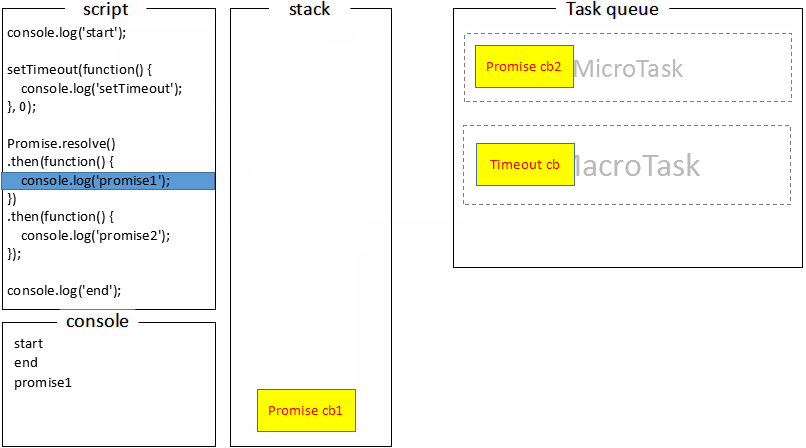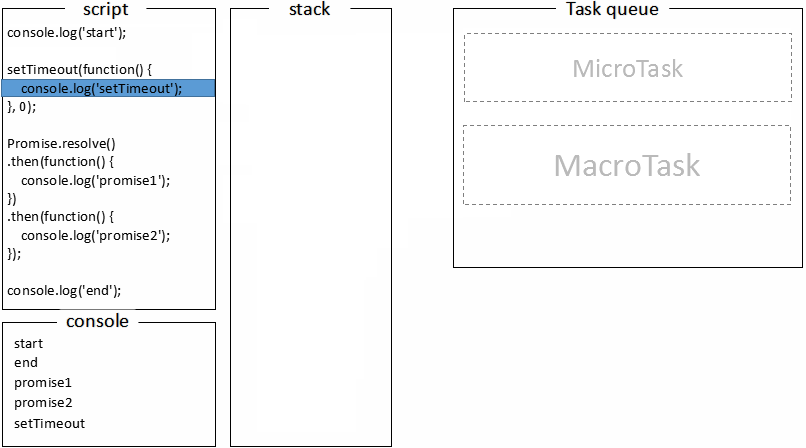
至此,浏览器里的事件循环机制就学得差不多了。这里需要引起注意的一点是,每次取的是一个宏任务,而宏任务与宏任务之间是一个微任务队列,可能具有多个微任务。而且微任务里如果执行了微任务,同样会将新的微任务添加到当前微任务队列最后面,所以新添加的微任务是优先于下一个宏任务执行的。
node 事件循环
const fs = require('fs')
fs.readFile('./file.js', 'utf8', () => {
setTimeout(() => {
console.log(9)
}, 0)
setImmediate(() => {
console.log(8)
})
Promise.resolve().then(() => {
console.log(5)
Promise.resolve().then(() => {
console.log(6)
})
})
process.nextTick(() => {
console.log(3)
process.nextTick(() => {
console.log(4)
})
})
console.log(2)
})
setImmediate(() => {
console.log(7)
})
setTimeout(() => {
console.log(1)
}, 0)运行结果为123456789或234567819: 事件循环过程为:
- setTimeout队列 => IO callback队列 => setImmediate队列 => setTimeout队列 => ...
- 过程中穿插 nextTick 队列 => promise 队列